
안녕하세요. 요즘 틈틈이 글을 올리고 있는 블로그 지기입니다.
이번 포스팅에서는 요즘 로컬 컴퓨터에서 많이 돌리는 wan에 대해서 적어볼까 합니다.
저도 배우고 있고 배우면서 시도했던 것 그리고 어떻게 하면
요즘 컴퓨터에 비해 사양이 낮은 내 컴퓨터에서 잘 돌릴까 연구하면서 하는 것 같네요.
그래서 번번이 실수도 많고 실패도 많습니다.
아래는 제가 쓰고 있는 하이, 로우를 이용한 cumfyui에서 wan을 돌리는 워크플로입니다.
단일 워크플로우 받기
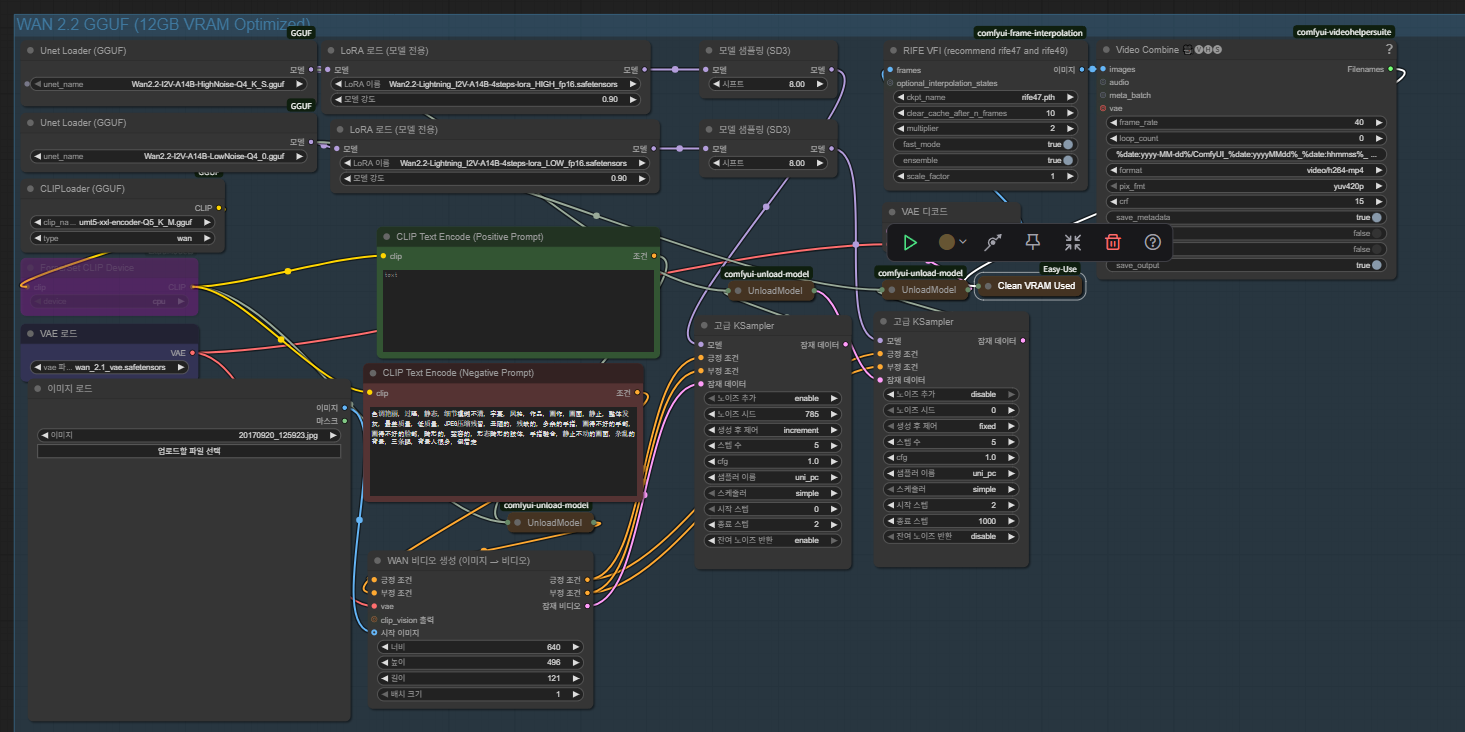
시작과 끝이미지로 영상 제작 워크플로
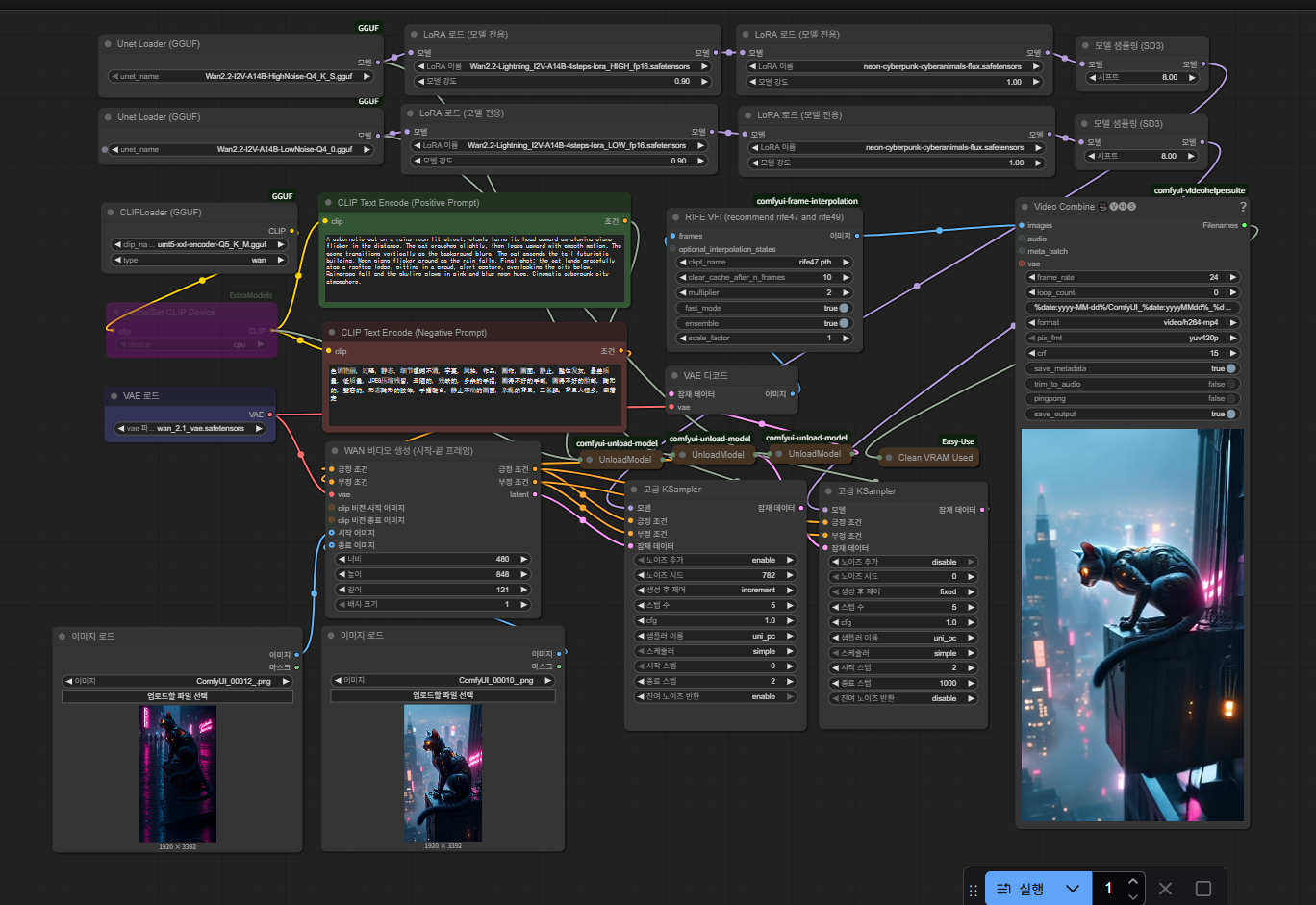
모델받기 전에 간단하게 설명을 드린다면
★WAN에서 하이/로우 모델 쓰는 이유
요즘 WAN 영상 만들 때 하이(High Noise) / 로우(Low Noise) 모델을 같이 쓰는 이유는 간단합니다.
🔹 하이 노이즈 모델 (초반 담당)
영상의 큰 구조나 레이아웃을 먼저 잡아줌
예: 인물 위치, 배경 구도, 동작 흐름 같은 큰 틀
🔹 로우 노이즈 모델 (후반 담당)
디테일, 텍스처, 표정, 빛 표현 등을 세밀하게 완성
영상 마무리 단계에 꼭 필요함

●왜 이걸 같이 써야 할까?
| 더 자연스러운 흐름 | 초반엔 구조, 후반엔 디테일 = 완성도 높은 영상 |
| 품질 안정성 | 흐릿하거나 흔들리는 걸 잡아줌 |
| 효율 | 처음부터 끝까지 무거운 모델 안 써도 돼서 빠르게 처리 가능 |
| 조절 가능 | ComfyUI에선 어느 타이밍에 전환할지도 설정 가능함 |
●속도와 메모리 최적화
모든 스텝에 무거운 통짜 모델 쓰면
→ GPU 메모리 폭발 or 속도 너무 느림
근데 처음 몇 스텝은 구조만 잡으면 되니까
→ 그땐 가벼운 하이 모델만 써도 충분함
♬ 그래서 고성능은 마지막 몇 스텝에만 쓰는 구조 = 리소스 아끼고 품질은 유지
●학습이 더 안정적
●같은 통짜 모델로 모든 노이즈 단계 학습시키면
→ 중간에 헛소리 나오거나 퀄리티 흔들림
● High / Low 나눠서 학습시키면
→ 각 스텝마다 더 정확하고 안정적으로 학습됨
요즘엔 양자화 버전들이 많이 나와서 각각 맞는 모델들을 찾아서 쓰곤 합니다.
WAN 2.2 용 베이스 하이/로우 베이스 모델받는 곳
https://huggingface.co/QuantStack/Wan2.2-I2V-A14B-GGUF/tree/main
QuantStack/Wan2.2-I2V-A14B-GGUF at main
huggingface.co
이곳에서 하이 로우 버전과 VAE 모델을 받으시면 됩니다.
제 환경은
5600x 3080ti(12g) 32 ram 쓰고 있습니다.
Wan2.2-I2V-A14B-HighNoise-Q4_K_S.gguf
Wan2.2-I2V-A14B-LowNoise-Q4_0.gguf
vae도 여기서 같이 wan_2.1_vae.safetensors 받습니다.
wan_2.2_vae.safetensors 나왔지만
아직 2.1과 호환이 잘 안돼서 2.1을 많이 사용합니다.
VRAM이 높으시면 더 높은 버전을 받으시면 좋습니다.
최근 Q8들을 많이 사용합니다.
현재 고속 라이트닝 노드는
양자화된 버전에 학습결과를 보장하는
스텝 lora를 연결해 쓰는 구조입니다.
LoRA는 여기서 “4 스텝까지 학습한 결과만” 사용 중
추가 학습은 없음, 지금 사용하는 LoRA는 이미 학습된 상태의 것을 “적용”만 함
LoRA 파일명도 4 steps로 확실하게 표기되어 있음
속도와 퀄리티 밸런스를 잡은 구조
→ Q4 GGUF + Lightning LoRA 조합 = 빠름 + 가볍고 + 꽤 괜찮은 퀄리티
lora모델 다운로드
http://huggingface.co/Kijai/WanVideo_comfy/tree/main/Wan22-Lightning
Kijai/WanVideo_comfy at main
huggingface.co
"현재 제가 쓰는 LORA모델은 4 스텝입니다."
Wan2.2-Lightning_I2V-A14B-4steps-lora_HIGH_fp16.safetensors
Wan2.2-Lightning_I2V-A14B-4steps-lora_LOW_fp16.safetensors
사양이 좋으신 분들은 8 스텝, 다른 스텝들도 써보시고 본인 취향에 맞는
버전을 찾아 쓰시면 좋을 것 같네요.
그리고 참고로 팁을 드리자면 만드신 그림의 경우 로라를
사용했다면 그 사용했던 이미지 로라도 연결하시면
인물 유지 할 때 더 잘되는 것 같습니다.
하이 로우에 같이 넣으시면 됩니다.
노드는 복제하시고 로라만 불러오시고 노드선을 연결해 줍니다.
텍스트 엔코더 모델 다운로드 경로입니다.
프롬프트를 추론해서 처리하는 모델입니다.
이것도 높을수록 더 좋은 결과를 가져올 수도 있습니다.
https://huggingface.co/city96/umt5-xxl-encoder-gguf/tree/main
city96/umt5-xxl-encoder-gguf at main
huggingface.co
역시나 제가 쓰는 모델입니다.
umt5-xxl-encoder-Q5_K_M.gguf
모델받는 곳들을 적어 드렸습니다.
약간의 VRAM이 있으시면
★Teacache, SageAttention을 노드에 넣어
속도를 조금 더 보강 할 수 있습니다.
https://memorywalker.tistory.com/16
Python +triton+SageAttention 조금 더 빠른 이미지 생성
요즘 ComfyUI 쓰시는 분들 중에 SageAttention 설치하다 막히는 분들 많으시죠? 저도 처음에는 휠(. whl) 파일 버전 충돌이 나서 고생했는데, 이번에 정리해본 설치법 공유드려요. comfyui나 스테이블 디퓨
memorywalker.tistory.com
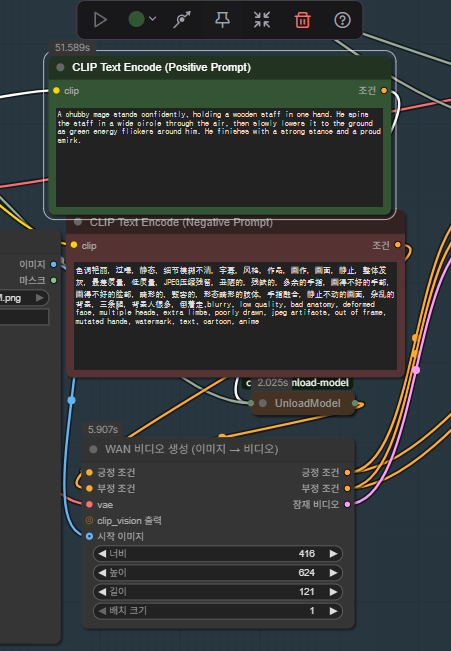


섬세하게 들어가실 분들이 아닌 경우
긍정프롬프트 : 이미지를 어떻게 움직이고 카메라를 어떻게 움직일 것인가,
피사체를 확실히 주입해 주는 것이 중요합니다.
부정 프롬프트:웬만한 건 중국어로 다 적혀있네요.
동영상 크기:너무 큰 경우 VRAM 오버로 작업이 중단될 수 있습니다.
보통 업스케일을 많이 사용합니다.
모델샘플링 시프트값:FLUX의 가이드, SD의 CFG로 프롬프트를 얼마나 따를 것인지에 대한 값입니다.
길이와 길이에 따른 프래임 레이트 계산만 하시면 될 것 같네요.
WAN 같은 경우 같은 프래임에 길이만 늘어나면 슬로 모션으로 나옵니다.
좀 더 부드럽게 하기 위한 길이일 뿐 그에 따른 프래임레이트 계산을 해주어야 됩니다.

짦게 적어 보았습니다.
좋은 영상들 많이 만드시길 바랍니다.

'설치가이드,Installation Guide' 카테고리의 다른 글
| ControlNet으로 이미지 포즈를 그대로 적용 -Canny에 대해 알아보자. (1) | 2025.09.16 |
|---|---|
| cumfyui 작게 만들고 ai로 선명하게 키운다 업스케일 모델 적용 (0) | 2025.09.14 |
| cumfyui용 flux kontext로 이미지를 바꿔보자 워크플로 포함 (0) | 2025.09.13 |
| Python +triton+SageAttention 조금 더 빠른 이미지 생성 (0) | 2025.09.10 |
| cumfyui로 나노 바나나 처럼 편집해보자 flux kontext(모델 가이드 포함) (0) | 2025.09.09 |



